I first came across the term “two-speed architecture” through an article from McKinsey Insights. I found it quite interesting as the topic applies to some of the projects and processes which I am currently involved in.
Some parts of this post contains distilled information from mckinsey’s articles on this topic, but other than that I have added some examples based on how two-speed practices are currently being implemented in several organizations. At the end of the post, I have provided a table which describes the dichotomy between the traditional world and the new world, which may (hopefully)harmoniously coexist in a “two-speed IT enterprise”
Introduction.
Two-speed architecture is a new terminology that is being used by some to describe the co-existence of a fast-speed customer-centric front-end running alongside a slow-speed, transaction-focused legacy back end. A two-speed IT architecture is aimed at helping companies develop their customer-facing capabilities at high speed while decoupling legacy systems for which release cycles of new functionality stay at a slower pace.
Those organizations which plan to modernize their application and system portfolio may find themselves following a two speed architecture through out the transitional period which could last few months to several years.
Microservices could act as a key enabling force for a two speed architecture though it is not a necessity. e.g. New microservices defining only a small amount of functionality, such as look-up of the next product a consumer would most likely purchase, should be deployable in an hour rather than in several weeks.
Main Drivers
There are many mature old economy companies which face significant market pressures to take advantage of cutting edge technologies to bring new products and services, improve time to market, provide richer user experience and improve operational efficiency through automation.
The legacy IT architecture and organization, for example, which runs the supply-chain and operations systems responsible for executing online product orders, lacks the speed and flexibility to address the above needs. In-order to address these issues, many companies need an IT architecture that can operate at different speeds.
Some examples include
- A traditional insurance company which aims to take advantage of latest GPS technology based services to track customer’s driving habit to provide a personalized insurance policy – here the service to track driving habit may be one or more microservices which may use semi-anonymous data to the extent that is permitted by the rules and regulations. These microservices will typically use their own data-stores and may exchange anonymous or semi anonymous data across other services in a way that is probably not imaginable in their own legacy systems.
- A traditional retailer which aims to offer new sales channel through mobile devices or which aims to provide a multi-channel experience to user – these new mobile apps will be written in latest front-end technologies and may try to take advantage of big data and advanced analytics to offer services such as buying suggestions. They may also aim to integrate with social media to take advantage of marketing possibilities offered, e.g. by enabling a user to post his latest purchase in facebook. These new ecosystem could have completely different requirements and capabilities when it comes to agility, security and time-to-market when compared to the same retailer’s traditional ERP systems
- An old economy financial giant can write a set of (micro)services to offer a set of services which access and integrates customers data from different departments of the bank (which are typically managed in silos and not integrated in a central repository) and possibly even from third party risk management solutions to process customer’s credit or loan application. Such an exercise which may have taken several days to weeks in the past using a combination of digital and manual actions could be done fully digitally in real time nowadays. But such a new microservice probably also has to be more agile with shorter release cycles, while individual legacy services which are glued together have different release cycles which cannot be coordinated for organizational reasons.
- An insurance company can launch an app which tracks user’s geographic location. When the user leaves the country, the app will recognize this and can push this information to a microservice. Another microservice can then recommend a travel-insurance to the user. These new microservices could have tremendous business value, but at the same time can be independently developed, tested and deployed in a more dynamic release cycle.
In a nutshell
Two speed architecture makes sense when a company with a portfolio of established “legacy applications” which demands high availability and high security with a slow release cycle is faced with the challenge of developing, testing and deploying customer facing front-end applications and services in a highly agile way to meet the market requirements. A two speed architecture is possible when a company makes a conscious choice to commit itself to “two speed IT” with the aim of addressing customer requirements and market competition using dynamic, shorter release cycles and relaxed customer-driven process and governance.
Following table shows some of the key differences between the two worlds that can harmoniously co-exist in a “two speed enterprise”.
[table]
Area or topic, Legacy applications and services, New (micro)services
Approach, “Waterfall / Waterfall-scrum hybrids / “pseudo-scrum””, XP / Scrum / Kanban – willing to adopt aggressive and tactical Devops practices from time to time to deliver software at short notice
Governance, “Plan driven, approval based”, “Empirical, continuous, process based”
Release cycle, One release per month or per quarter,”Several releases per month, sometimes several releases per week”
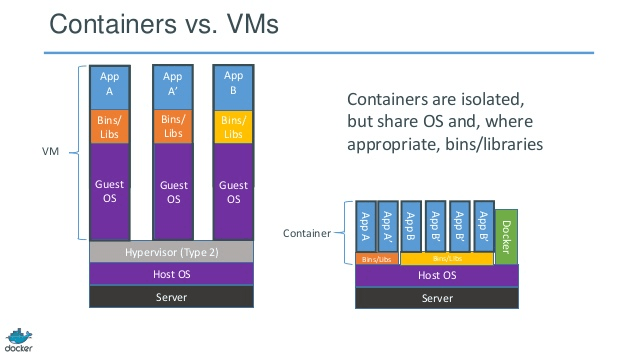
Release process, “Manually intensive releases, often with extended downtime”, “Fully automated releases, sometimes delivered using container based packaging and deployment tools like Docker with minimal service disruption”
Testing, “Unit tests written by developers, often followed by a dedicated QA team performing testing in a lengthy QA phase”, Relatively less number of unit tests and highly automated end-to-end integration tests
Testing, Emphasis on full test coverage using traditional test coverage metrics – not transparent to all the stakeholders, “Emphasis on monitoring and recovering capabilities using modern DevOps tools and practices. POs, Ops and developers are able to view the status and health of services in a highly transparent manner using monitoring pages in a web browser”
Operation, Emphasis on robustness – highly risk averse and willing to postpone releases if confidence is missing, “Emphasis on time to market – willing to take calculated risks for bringing new features as early as possible, thus gaining valuable end user feedback (fail fast, fail often)”
Architecture, “Default mode of thinking will be a layered architecture resulting in classic 3 tier architecture of UI, middleware and DB”, Architecture is API driven and thinking is dominated by disparate services that are required to solve a domain problem.
Culture, IT-centric / process-centric, Business-centric
[/table]
Followers
Insurer Allianz is known to have made “two speed architecture” a core part of their enterprise IT strategy. Australian Department of Defense is also known to have taken such a stance. According to some consultancies such as McKinsey and BCG, several retailers, banks and telecoms are said to have aligned their IT process and architecture for a two speed architecture, but their names seem to be a closely guarded secret.
References
- http://www.mckinsey.com/insights/business_technology/a_two_speed_it_architecture_for_the_digital_enterprise
- http://www.mckinsey.com/insights/business_technology/running_your_company_at_two_speeds
- http://www.wired.com/2014/12/reach-two-speed-it-apis/
- https://www.bcgperspectives.com/content/articles/it_performance_it_strategy_two_speed_it/
- Coursera provides a free course on the broader concept of “Two Speed IT”, aimed at IT strategy managers
- API centric development